Our Process
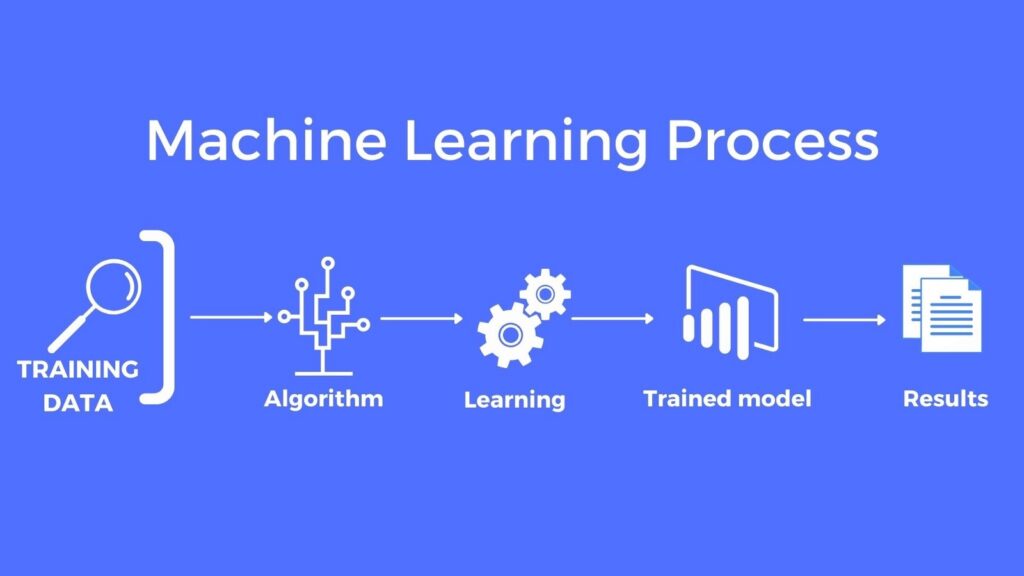
Our model tries to explain the underlying factors between mergers and the resulting economic value added so investors can accurately invest and be reasonably helped with their investments. Our plan revolved around much previous research that was done, however, for this field.
Previous Work
Typically, the approach used to predict mergers has been using logistic regression to predict the economic value added of a merger. Still, with the rise of machine learning, it shows a prominent application in the field. Sixty-two percent of the cases were appropriately predicted by the logistic regression results utilizing the rate of EVA parameter, which shows that mergers have the potential to be accurately predicted (Leepsa & Misra, 2017).
However, researchers such as Hellesøe and Hellevik proved that machine learning models, specifically Random Forest models, allow for superior prediction than Logistic regression when identifying acquirer success factors (Hellesøe & Hellevik, 2023).
Actually, takeover targets in M&A have been predicted using machine learning models in the past. Comparable models created to forecast M&A performed worse than the GraphSAGE model. Researchers developed a model with 47.62% target and 83% non-target classification performance using a dataset from Greek enterprise companies (Tsagkanos et al., 2007).
Despite the dismal results, according to the researchers, the graphSAGE model illustrates a useful application of machine learning. The most useful and effective application of machine learning, however, has been to identify relationships between the language of a company’s 10-9K filing and the likelihood of their eventual merger.
In order to forecast mergers in the banking sector, Katsafados et al. aimed to employ a machine learning textual-based model (Katsafados et al., 2021). Because of the opaque phrasing, their results were only contradicted by the nature of the banking sector (Katsafados et al., 2021). Because of this, machine learning models that use decision trees and random forests have been used, however the results do not match the higher expected scores
How did we create this model?
We had to choose the kind of model that would work best for the research before I could use it in this program. In my instance, We made the decision to employ a neural network to modify each node’s weight in order to ascertain which factors were more important in forecasting a merger’s success.
This will help me better comprehend my data once I’ve completed training and testing each model. Nodes are used by neural networks to identify the optimal output result. We are then able to accurately ascertain which components are most important in influencing the output.
We Referenced This Amazing Video By 3Blue1Brown
The XML file link provided by EDGAR searches allows you to parse the data that was extracted from the sec.gov website using the EDGAR database. This information was taken from the pre-merger “x” amount of the two companies and compared to their post-merger valuation. In order to reduce the model’s bias toward a particular merger industry, this data was manually fed into the model using 50 randomly chosen pre- and post-merger mergers.
The equation EVA = NOPAT – (WACC * capital invested) is how we calculated Economic Value Added (EVA). Due to the past failure of conventional techniques, including stock price calculations, to be meaningful, EVA has become the primary method utilized in merger calculations. Nonetheless, the EVA provides a more realistic assessment of the benefits of a merger to a company. But to compute the model with a neural network, the nodes must be trained toward the numerical value without utilizing a particular equation.
Initially, the Economic value added (EVA) computation was done by hand; however, it was later trained into the model. After that, the model was trained by manually modifying the weights to ge the final valuation by aligning the most likely components. One advantage of the neural network paradigm was this. Consequently, we would employ the neural network to ascertain whether a merger would be successful.
Each weight was manually adjusted until we proved the values of each metric.